基础爬虫
背景#
众所周知,爬虫是主动漏洞扫描中极其重要的一环。在漏洞扫描中,爬虫被用作一种数据收集工具,用于获取目标系统的信息以帮助我们发现漏洞。
Yakit 漏洞扫描中的基础爬虫通常包含以下三个主要步骤:
网站爬取:爬虫首先会爬取目标系统中的网站,并将网站的源代码和相关信息存储到扫描器的数据库中。这些信息包括网站的URL、页面结构、表单、脚本和其他与网站相关的信息。
爬取数据分析:基础爬虫会对爬取的网站数据进行分析,并从中提取相关的信息,如网站的结构、链接、表单和参数等。
漏洞检测:基础爬虫会使用爬取到的信息根据加载的相关的Yakit插件进行漏洞扫描,并根据扫描结果提供相应的漏洞报告。
需要注意的是,漏洞扫描中的爬虫与普通的爬虫有所不同。它并不是为了抓取网站上的数据而设计的,而是为了获取网站结构和参数等信息以帮助我们发现漏洞。同时,进行漏洞扫描时需要遵守相关的法律和道德规范,不能进行未经授权的攻击行为。
使用方法#
在输入框中输入 IP / 域名 / 主机名 / URL,多目标可以逗号分隔,点击开始执行即可开始爬取
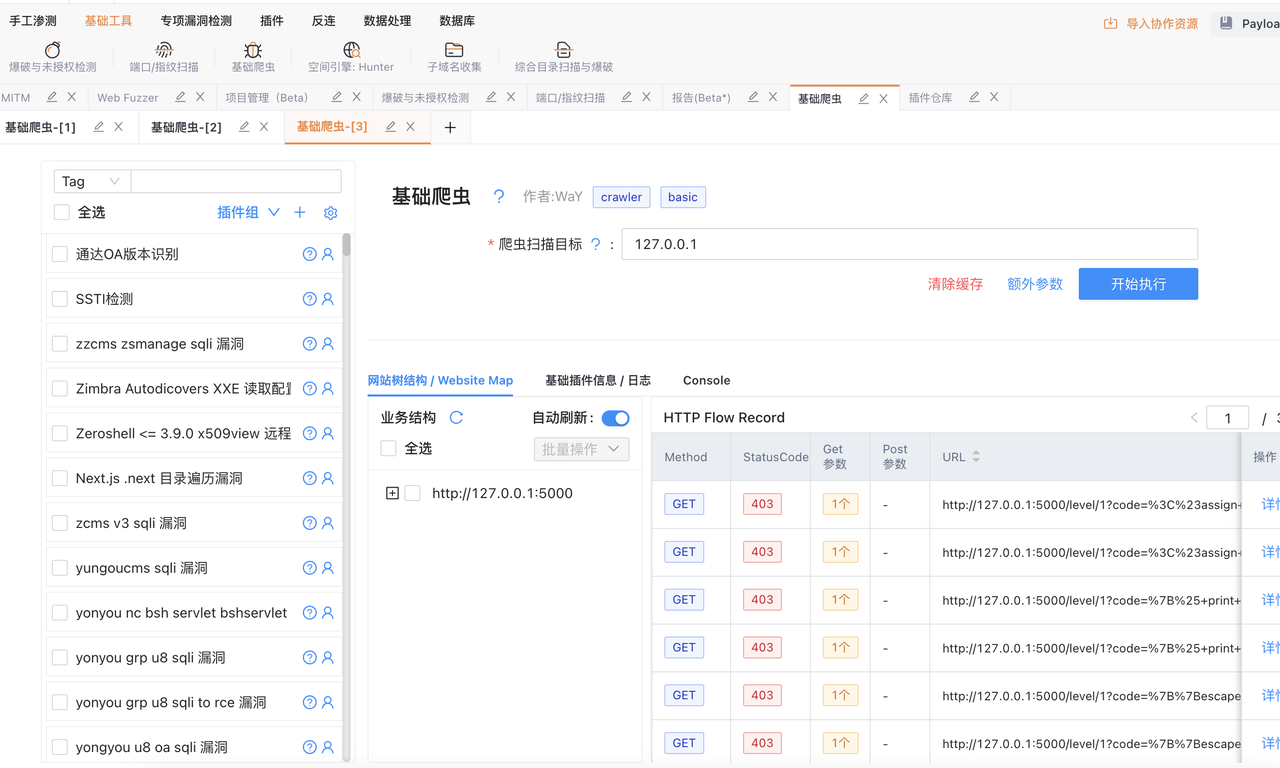
更多参数#
额外参数可设置更多内容,方便爬虫更好运行。
- 参数说明:
- 设置代理:有些网站访问不到的,可以加入代理进行访问,格式为http://127.0.0.1:7890 或者 socks5://127.0.0.1:7890
- 超时时间:每个请求的最大超时时间
- 最大深度:设置爬虫的最大深度(逻辑深度,并不是级数)
- 并发量:爬虫的并发请求量(可以理解为线程数)
- 最大URL数:爬虫获取到的最大量URL(这个选项一般用来限制无限制的爬虫,一般不需要改动)
- 最大请求数:本次爬虫最多发出多少个请求?(一般用于限制爬虫行为,一般不需要改动)